



Spotnana’s Event-Driven Architecture, Part 2
Our initial Gossiper event processing framework served us well in the first phase of production traffic. However, as the workflows evolved to be more complex, the producer and consumer pattern became intermingled with too many topics and consumers, and the desired flow was hard to maintain and update.
Moreover, for certain scenarios, the workflow needed to maintain a temporary state, and it required support to schedule events at a specific time or frequency. Our team ultimately decided that it was time to expand our event processing framework into a workflow engine with greater capabilities.
We realized that we needed to design a workflow engine that supported scheduling and state management, while allowing developers to write complex workflows seamlessly. We also needed to design a workflow engine that had beneficial properties like scaling, reliability, ordering, and error handling. We chose Kafka Streams as the core platform upon which our new workflow engine, GossiperFlow, was built.
Before building this workflow engine, we identified the following requirements:
- Executing Generic Workflows – We need to build a ‘workflow’ engine that meets our requirements for scalability, reliability, ordering, and error handling.
- Scheduling – The ‘processors’ should be able to schedule or invoke a certain processor at a specified time in the future with a specific message. This allows for scheduled time-based actions, such as refunding the held amount on a user’s credit card if the corresponding booking is canceled or declined by the airline.
- Retries – The workflow engine should allow for retrying a configurable number of times.
- Idempotency – The processing logic calling external systems must be idempotent on their own. Otherwise, it could lead to unwanted side effects.
- Processing Semantics – The workflow engine should provide Exactly-Once processing and semantics should support an idempotent state. For instance, incrementing an integer in the state should never lead to double counting or missed counting.
- Rolling Forward and Backward – We should allow for manual intervention in case of unrecoverable errors, including the ability to roll a workflow forward or backward as required.
With these requirements in mind, we designed the GossiperFlow workflow engine to include these major components: Workflow Processor, Workflow Driver, Scheduler, and StateStore.
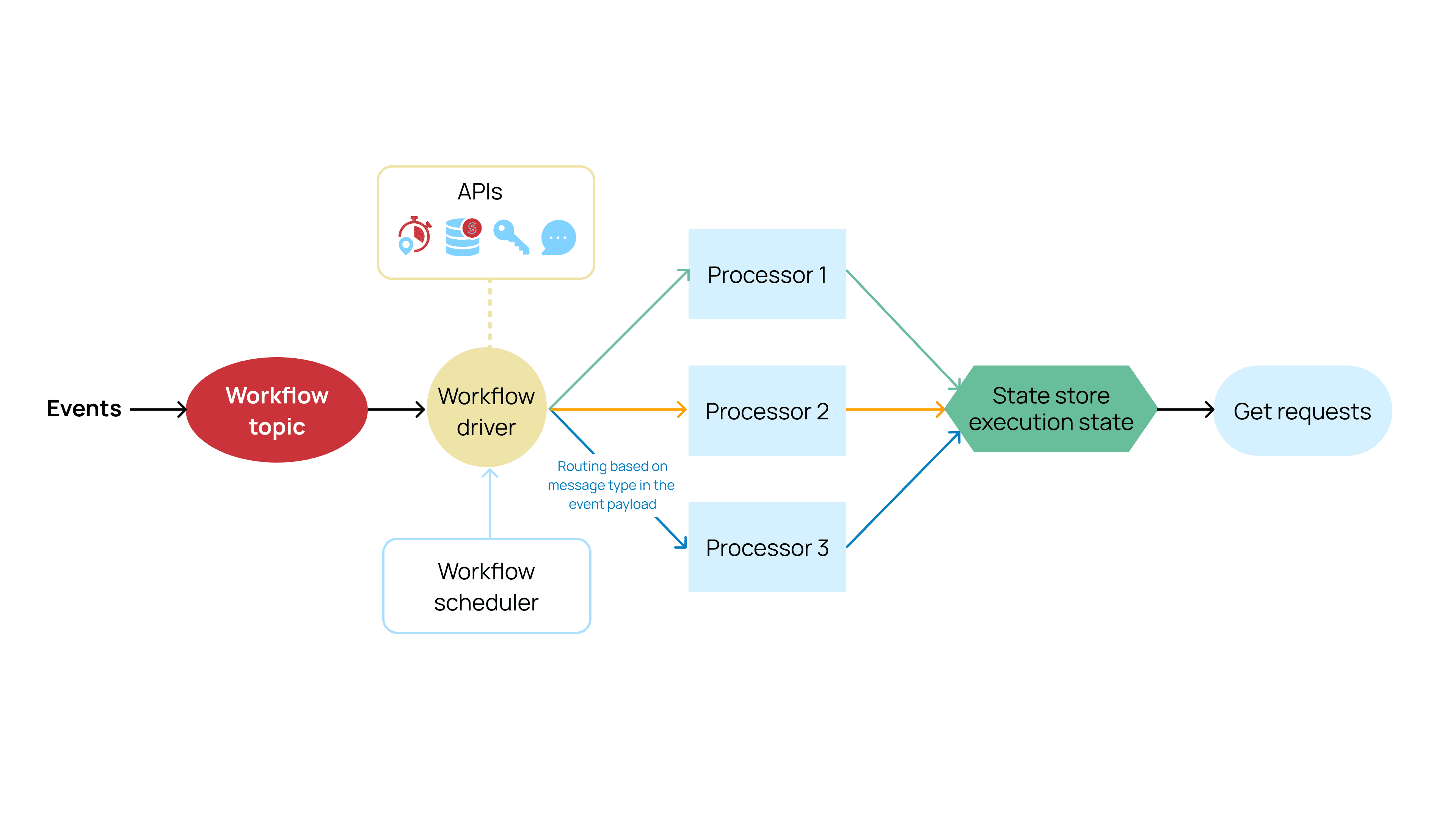
Diagram 2 – Components of the GossiperFlow framework
To process workflows, our new workflow engine provides a base processor class, which needs to be used by the developer to implement workflow logic in the process method. When a processor receives an event payload, it has read and write access to the <key, value> based state store in order to persist any stateful data and read the current execution state to decide the next set of steps in the workflow.
In order to drive workflows, there is one Kstreams transformer node instance per workflow. This takes a set of processors as input and drives the workflow forward by calling the appropriate processor class based on the message type received in the event payload.
At a given time in the future, workflow processors can use the workflow engine to subscribe to a callback for a given processor. This process is driven by the scheduler. One key value state store instance is provided by the workflow engine to the processor classes to store their workflow data and the execution state.
GossiperFlow Implementation and Impact
To implement GossiperFlow, we created an instance of Kstreams topology with only one transformer, with the source and sink being the same topic. One instance of Kstreams transformer class was created for every Kafka partition of the associated topic. The workflow engine provides a WorkflowDriver class, which takes the WorkflowConfig as input, containing a mapping from the message type to the respective processor classes to be called. The WorkflowDriver class derives from the Transformer class provided by the Spring Cloud Stream’s Kafka streams library.
The driver class maintains an internal state store for scheduling purposes. The store contains timestamp + uuid as the key and ScheduleStoreInfo as the value, containing the key, processorType, and the payload with which the corresponding processor will be invoked at the pre-scheduled time. The class exposes a schedule (timestamp, key, msgType) method, which is used by any of the processors to subscribe to timer callbacks. Within this method, a new key with timestamp + uuid is created and stored in the schedule-store with the value containing (key + msgType).
The workflow engine uses the Punctuate API provided by the Kafka streams library to receive periodic callbacks. Upon every callback, the workflow engine searches the internal state store (using a range query between “0” and “current timestamp”) to find and invoke the set of processors requiring a timer callback invocation. Then it deletes all the processed keys from the store to ensure duplicate invocations aren’t made. Given that Kafka streams support Exactly-Once semantics for transactions within Kafka, the aforementioned operations are executed atomically.
The workflow engine instantiates and provides access to the state store required by the processors to maintain their workflow data, i.e. states and stores. The GET APIs to the state store are provided as a service to the application, which is built as an abstraction over the Interactive Query APIs. However, this requires logic to issue an RPC call to a remote service instance to fetch the <key, value>. It is stored in the partition assigned to the remote instance in case the key doesn’t belong to the locally assigned topic partitions.
GossiperFlow plays a significant role in delivering unparalleled travel experiences to our customers. Specifically, our new workflow engine has enabled us to perform the following functions that support travel for our customers:
- Synchronizing – Sync booking confirmations and updates from all travel suppliers regarding air, hotel, car, and rail in a scalable and fault tolerant manner.
- Persisting downstream – After every booking is created or updated, reliably persist information in downstream systems including analytics, reporting, and accounting, and trigger email and push notifications.
- Polling – Poll third party APIs for travel updates, such as flight schedule changes, delays, cancellations, gate changes, seat updates, cabin upgrades, and hotel room upgrades. Then trigger appropriate actions, such as notifying the traveler and support agent, and take further actions based on the traveler’s response.
- Managing hard approvals – If a hard approval workflow is required by a travel policy, push out an email and mobile app notification to the travel approver and automatically cancel the booking if the approval is denied or if no response is received in a stipulated time.
- Optimizing travel management – Automate processes to rebook cheaper fares for the same itinerary, or change the seat to window or aisle based on traveler’s preferences.
- Handling errors – Automatically perform bookings via third-party APIs, process payments, and notify downstream microservices, while handling errors at every individual step.
As Spotnana scales in the years ahead, we will continue to evolve our event-driven architecture, so that it continues to power unparalleled travel experiences.
-
 How We Designed Spotnana to Support White LabelingA white labeled product is a software product or a service that is developed by one company and then rebranded and sold by another company. Users of the rebranded product are often unaware of...
How We Designed Spotnana to Support White LabelingA white labeled product is a software product or a service that is developed by one company and then rebranded and sold by another company. Users of the rebranded product are often unaware of... -
 Rings of ValidationSpotnana’s Travel-as-a-Service Platform is used by a wide range of personas including travelers, travel arrangers, company administrators, travel agents, and travel management company (TMC) administrators. When new features are ready, we have to ensure...
Rings of ValidationSpotnana’s Travel-as-a-Service Platform is used by a wide range of personas including travelers, travel arrangers, company administrators, travel agents, and travel management company (TMC) administrators. When new features are ready, we have to ensure... -
 Spotnana’s Event-Driven Architecture, Part 1Spotnana is building a modern, open, API-driven platform for the $1.4 trillion travel industry, which has relied heavily on technology that was developed in the last century. Corporate travel involves complex workflows, including airline,...
Spotnana’s Event-Driven Architecture, Part 1Spotnana is building a modern, open, API-driven platform for the $1.4 trillion travel industry, which has relied heavily on technology that was developed in the last century. Corporate travel involves complex workflows, including airline,...