


Spotnana’s Event-Driven Architecture, Part 1




Spotnana is building a modern, open, API-driven platform for the $1.4 trillion travel industry, which has relied heavily on technology that was developed in the last century.
Corporate travel involves complex workflows, including airline, hotel, car, and rail bookings, trip modifications, payments, email notifications, invoice generation, and persisting data for analytics and financial accounting. These workflows need to be executed seamlessly in order to support travelers and drive growth for our customers and channel partners.
To address these needs, we have developed an event-driven architecture that automatically triggers actions or processes in response to specific events. The events we process can be driven by users or by external parties, such as an airline that sends us real-time information on flight schedule changes, gate changes, cabin upgrades, and cancellations. Given the volume of the events we need to handle and the intricacy of actions we need to take, we made the easy decision to use a fault tolerant event-driven programming paradigm.
Our initial event processing framework
Since the early days of Spotnana, we have utilized a cloud native microservices-based architecture. Because this architecture has been built with a cloud first mentality, our architecture has the ability to support multiple cloud providers. The back-end microservices communicate via gRPC protocol for synchronous communication. For asynchronous communication, an in-house library built over the Kafka platform is heavily used to process events and execute complex workflows in a distributed, horizontally scalable, and fault-tolerant manner. Protobuf, the payload format, is used for communicating over Kafka topics.
During Spotnana’s first year, our team wrote our very first event processing framework. We named it “Gossiper,” and it was an in-house library which served as an easy-to-use wrapper over the Apache Kafka framework. We used the basic producer and consumer pattern to publish the events, and process them via various downstream consumers to invoke necessary actions.
Before writing our Gossiper in-house library, our team identified the following requirements:
- Scalability – The system should be able to horizontally scale to support a high throughput of messages under stress load.
- Reliability – The application must be resilient to process and machine crashes, network failures, and service unavailability.
- Ordering – The messages for a particular entity must be received in the exact same order. For instance, the updates for a booking must be produced and processed in the same order as they actually happened.
- Retries and Error Handling – The system should be able to gracefully handle errors and exceptions while processing, perform retries as required, and raise an incident if the processing eventually fails.
- Debugging and Production Handling – We must implement a seamless way for the developers to capture any processing failures, diagnose the message payloads, purge any records, and be able to manually reprocess any messages.
When implementing our in-house library, our goal was to provide a simple interface our client applications could use in a user-friendly, error-proof manner. We applied this thinking to the work we did with our producer and consumer configurations.
To produce a new message, the producer only needs to provide the following: the topic name, the payload delivered as any protobuf message, and the partitioning key used for selecting the Kafka topic partition on which the message will be produced. The producer supports the publishing of any type of protobuf message on a single topic, and the consumers can process a subset of required message types while ignoring others. The library provides pre-configured implementations for the common producer configurations: supporting strong ordering and consistency guarantees, as well as allowing for high throughput event processing variation.
public interface GossiperProducer<T> {
/**
* Writes the ‘message’ to the given ‘topic’.
*
* @param topic Gossiper topic to which writes will be performed.
* @param key The key associated with the input ‘message’ which is used for choosing the partition to write to. If the given ‘key’ is null, any random partition of the topic would be picked.
* @param message The payload which will be written to the topic.
*/
void send(String topic, T message, String key);
}
For common consumer configurations, our team created custom, easy-to-use annotations. This enables applications to simply write a method and annotate it with the appropriate config to start consuming specific messages from the topic.
For example, a consumer which needs strong consistency, automatic retries, and error handling can use the custom annotation @GossiperConsumerSafe by providing the topic name and also the group_id and the message_type they are interested in.
@GossiperConsumerSafe(id = “group_id”, topics = “topic”, properties = “clazz:$class1”)
void process(Event event) {
// Perform operations …
}
Features of the Gossiper library
When our first customers booked travel through the Spotnana Travel-as-a-Service Platform, all requests were processed through our Gossiper library. The following diagram depicts a partial booking flow using the Gossiper library, with features of our event processing framework explained beneath it:
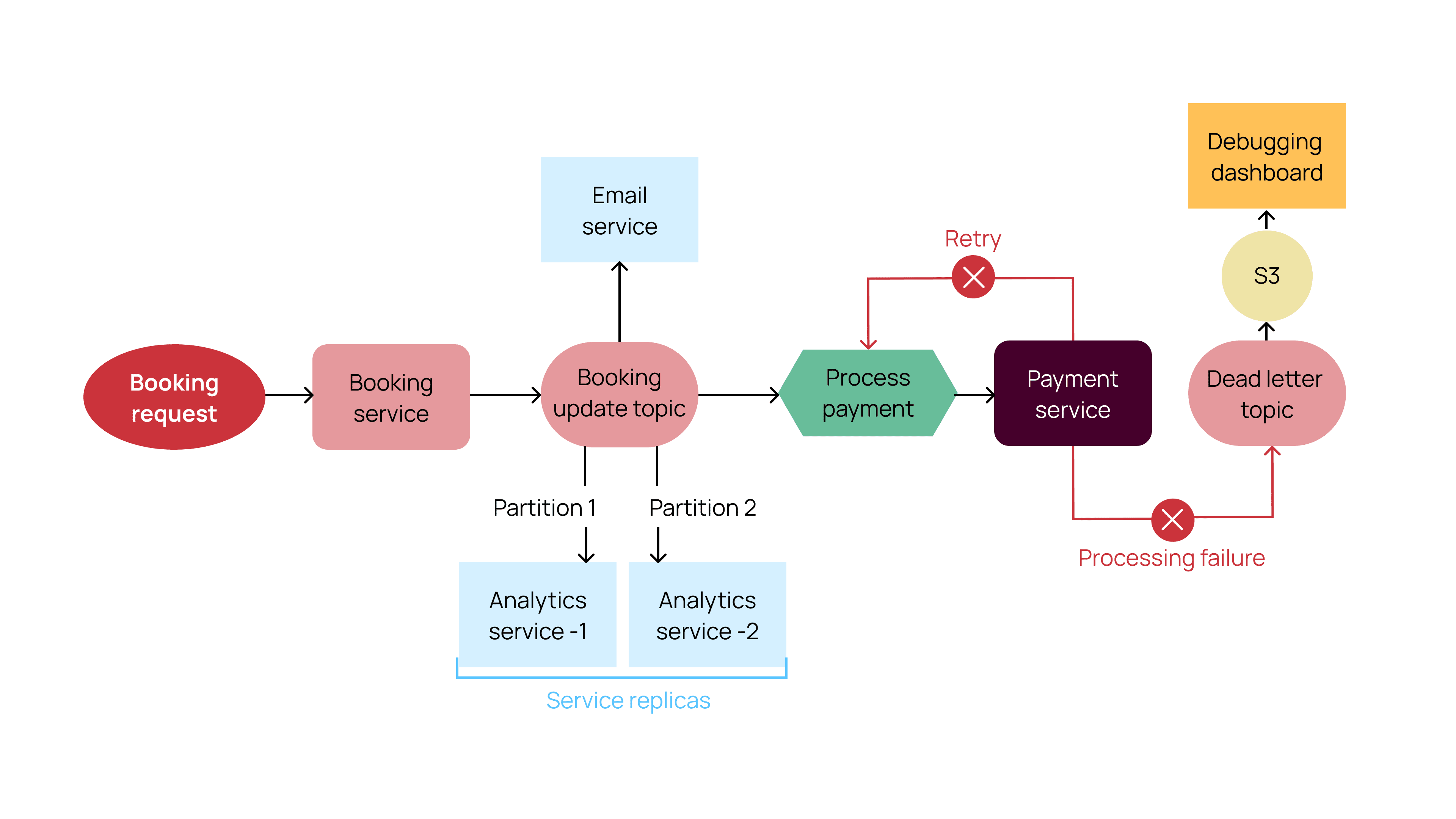
Diagram 1 – Partial Booking Flow using the Gossiper Library
A key feature of this framework is that it is horizontally scalable. As the load on a given microservice increases (e.g., heavy computation, too many messages to process), it is set up for auto-scaling in the cloud deployment. This means that the number of instances will increase or decrease in proportion to the load.
All the instances of a service are auto-assigned to the same Kafka consumer-group by the Gossiper library. This ensures that all the messages on the topic are shared among the set of service replicas, with each instance listening to one or more Kafka partitions. For example, in Diagram 1, there are two instances of the Analytics microservice running. They consume one partition each from the ‘booking update’ topic. We configured the topic partitions to be a high number, or more than the potential number of service replicas, so that Kafka is able to share the partitions among the available instances for load balancing.
Certain workflows need strong ordering guarantees for the consumers to behave correctly. For example, if a booking is confirmed and quickly canceled, and the updates to the downstream system are received in reverse (i.e. canceled followed by confirmation), it could lead to unintended behaviors. The library provides a strong ordering guarantee while publishing and consuming the messages on a topic. This is achieved by the following:
- Partitioning – while publishing a message, the producer provides a partitioning key, which is used to select the topic partition on which the message is published. Kafka ensures that the messages from the partition are consumed in the same order. For example, in Diagram 1, the partition key is the booking_id , which uniquely identifies a booking in the system. This ensures that all the updates for a particular booking are published on a fixed partition of the topic, which is consumed serially.
- Producer Config – Gossiper sets enable idempotence=true in the Kafka producer configuration to ensure that duplicates and out of order messages aren’t published.
Another key feature of this event processing framework is that it is fault tolerant. The system is resilient to machine, process, and network failures because misbehaving services will be marked dead by the Kafka broker and replaced by service replicas. Hence, the messages keep getting processed in the original order by the new instance owning the orphaned partition. Moreover, the consumers are configured to perform a specific number of retries if the processing logic has temporary errors, such as not being able to reach a database, cache, or elastic-search, or a glitch in an API response.
Lastly, this framework is adept at handling errors. If processing still continues to fail after all possible retries, then the message is redirected to a ‘Dead Letter Topic.’ Here, a processor delivers the message and related metadata into a S3 bucket that is connected to our internal debugging tools, making debugging easy for the developers. For example, in Diagram 1, if the consumer in the payment service throws an exception leading to multiple retries, the message is eventually pushed to the DLT and S3 if the retries are exhausted.
While our Gossiper library was a great start, we quickly recognized we needed more functionality to support our advanced workflows. Our Event-driven Architecture Part 2 post describes how we evolved Gossipier into a workflow engine that includes state management, scheduling, and other capabilities.
-
 Why Spotnana is more than an OBTWhen evaluating travel technology solutions to power their corporate travel programs, many companies focus primarily on the online booking tool (OBT), which is the visible interface where travelers book trips. It's the infrastructure powering...
Why Spotnana is more than an OBTWhen evaluating travel technology solutions to power their corporate travel programs, many companies focus primarily on the online booking tool (OBT), which is the visible interface where travelers book trips. It's the infrastructure powering...

-
 2025 year in reviewAs we close out 2025, we're reflecting on a year defined by growth, innovation, and deepening partnerships across the travel ecosystem. From launching transformative products to expanding our global content network and welcoming new...
2025 year in reviewAs we close out 2025, we're reflecting on a year defined by growth, innovation, and deepening partnerships across the travel ecosystem. From launching transformative products to expanding our global content network and welcoming new...